Models
Choosing the Best Embedding Model for Local Search
Compare embedding models for retrieval, semantic search, and document clustering on local hardware.
Choosing the Best Embedding Model for Local Search
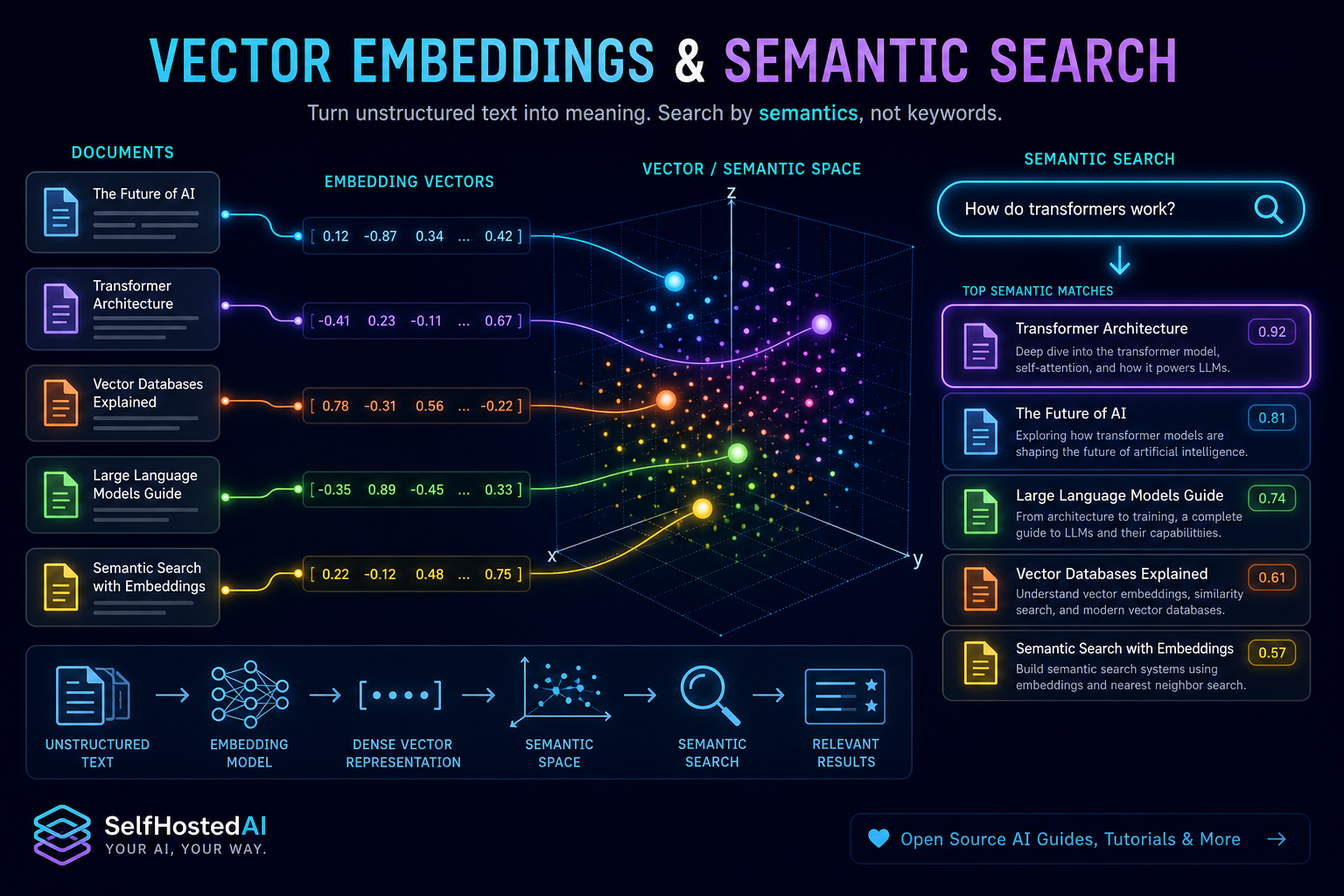
Embedding models power the retrieval part of local AI. They turn text into vectors so documents with similar meaning can be found even when the wording is different.
Match the model to the workload
Choose a model based on language support, speed, memory use, and retrieval quality. A small fast model may be enough for personal notes, while larger or specialised models can perform better on mixed technical documents.
Use Best Local AI Models for Beginners to frame the wider model selection process.
Compare a few real queries
Do not pick by benchmarks alone. Test your own documents with a handful of real questions and see which model retrieves the right passages most often.
Look for stable semantics
Good embeddings should keep related passages close together even when wording changes. If the search results feel erratic, the model may be too small or the corpus may need cleaner preprocessing.
Balance speed and quality
Embedding generation should be fast enough to keep ingestion practical. If indexing becomes painfully slow, the team will stop using it. That is why speed matters as much as retrieval quality.
For search workflows in a local interface, see Open WebUI Setup for Local Documents.
Conclusion
The best embedding model is the one that reliably finds the right source passages for your documents. Start with your own queries, not someone else’s benchmark chart.
FAQ
Do I need a huge embedding model?
Usually not. Smaller models are often good enough if the corpus is clean and the retrieval pipeline is tuned well.
Should embeddings and chat use the same model?
Not necessarily. Retrieval and generation are separate jobs.
Can I switch embedding models later?
Yes, but you may need to re-index your document store.


