Models
Prompt Chaining: Connect Multiple Prompts for Better Local AI Results
Chain short, focused prompts together to produce better results than one giant instruction with local models.
May 31, 2026 - 7 min read
Category
Local LLMs, embedding models, quantization, and model selection.
Models
Chain short, focused prompts together to produce better results than one giant instruction with local models.
May 31, 2026 - 7 min read

Models
Compare Mistral, Llama, and Qwen model families across performance, hardware fit, ecosystem support, and practical use cases.
May 31, 2026 - 10 min read

Models
Install DeepSeek R1 locally, configure quantised variants for consumer GPUs, and build a private reasoning workflow that keeps data off third-party servers.
May 31, 2026 - 10 min read
Models
Install and run Qwen 2.5 models locally with Ollama or vLLM, compare size variants, and deploy them for chat, coding, and multilingual tasks.
May 31, 2026 - 9 min read

Models
Run Phi-4 locally on modest hardware, understand why its small size punches above its weight, and integrate it into practical workflows.
May 31, 2026 - 8 min read
Models
Install Gemma 3 locally with Ollama or Hugging Face, compare sizes, and build privacy-first workflows on Google's efficient open-weight architecture.
May 31, 2026 - 9 min read

Models
Understand GGUF quantisation levels, choose Q2 through Q8 for your hardware, and balance quality against VRAM usage for every local model.
May 31, 2026 - 10 min read
Models
Compare embedding models for local retrieval-augmented generation, from BGE to E5 to Nomic Embed, and choose the right one for your document pipeline.
May 31, 2026 - 9 min read

Models
Match embedding models to your document domain — code, medical, legal, or technical — for significantly better local RAG retrieval quality.
May 31, 2026 - 10 min read

Models
Liquid AI's new LFM2.5-8B-A1B packs 8B total parameters (1B active) with a 128K context window, trained on 38 trillion tokens, and runs on llama.cpp, MLX, vLLM and SGLang from day one.
May 31, 2026 - 4 min read

Models
Liquid AI released LFM2.5-8B-A1B, a Mixture-of-Experts model with only 1B active parameters per token, a 128K context window, and day-one support for llama.cpp — making it one of the most efficient models for local inference.
May 30, 2026 - 9 min read
Models
Liquid AI's LFM2.5-8B-A1B is an 8B-parameter MoE model with only 1B active parameters, trained on 38T tokens with 128K context — and it runs on consumer hardware via llama.cpp and GGUF.
May 30, 2026 - 10 min read

Models
Alibaba's Qwen team releases Qwen-VLA, an embodied foundation model that unifies vision, language, and continuous action generation across diverse robot platforms.
May 30, 2026 - 3 min read
Models
Combine a small fast model and a stronger reasoning model to balance speed, cost, and quality.
May 29, 2026 - 10 min read
Models
Match model size to your hardware, latency target, and task before you chase benchmark hype.
May 27, 2026 - 8 min read
Models
Understand what 4-bit, 5-bit, and 8-bit quantisation actually mean for speed, quality, and memory.
May 26, 2026 - 9 min read
Models
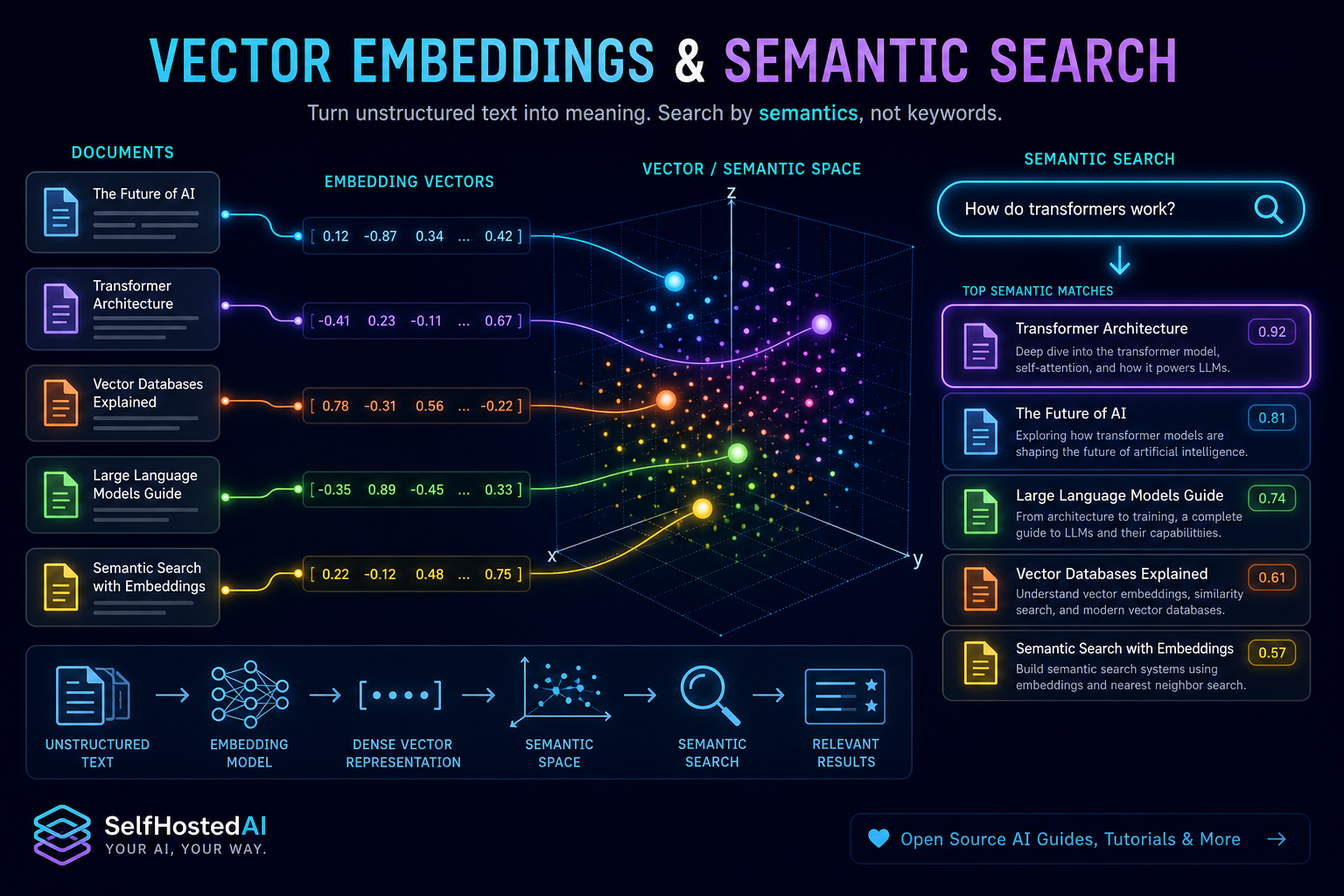
Compare embedding models for retrieval, semantic search, and document clustering on local hardware.
May 24, 2026 - 8 min read
Models
Use clearer instructions, better context, and repeatable prompt patterns to improve local model output.
May 24, 2026 - 8 min read
Models
A beginner-friendly map of local model types, sizes, and practical first choices.
May 13, 2026 - 8 min read