Tutorials
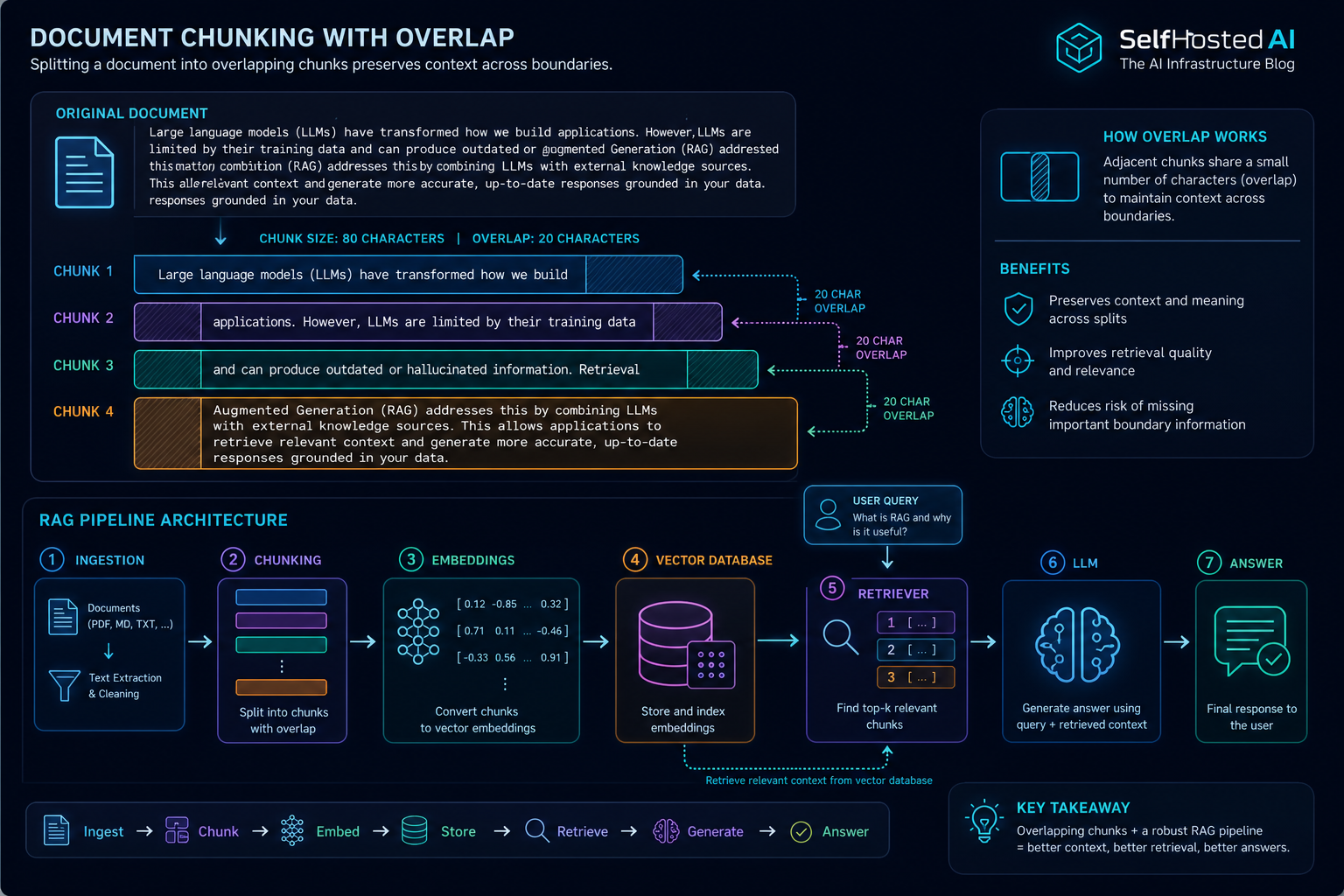
Tune Chunk Size and Overlap for Better Retrieval
Find better RAG results by tuning document chunk size, overlap, and structure for your corpus.
Tune Chunk Size and Overlap for Better Retrieval
Chunking is one of the easiest ways to improve or ruin retrieval quality. If your chunks are too large, search becomes noisy. If they are too small, the answer loses context.
Start from document structure
Use headings, paragraphs, and natural boundaries where possible. A chunk should hold one coherent idea, not a random slice of prose.
For a practical setup, see How to Index Local Documents Safely on a Private Server.
Adjust overlap carefully
Overlap helps preserve meaning across boundaries, but too much overlap creates duplicate noise in retrieval results. Increase it only when you see context being cut off too aggressively.
Test on real documents
Chunk settings should be chosen from real files, not assumptions. Manuals, policy documents, meeting notes, and code docs may each need a slightly different approach.
Watch for answer duplication
If the model keeps repeating the same section or pulling nearly identical chunks, reduce overlap or improve metadata filters. Retrieval should feel focused, not repetitive.
Read Build a Local RAG Pipeline That Actually Answers Questions to connect chunking to the wider pipeline.
Conclusion
Chunk size and overlap are small configuration details with big consequences. Tune them against your real corpus and keep iterating until retrieval feels natural.
FAQ
Is there one perfect chunk size?
No. It depends on document structure, model context window, and query style.
Should overlap always be used?
Usually yes, but only enough to preserve meaning across boundaries.
Do headings matter?
Very much. Headings make it easier to preserve context and relevance.


